
La caída global de Internet del 18 de noviembre dejó desconectados a millones de usuarios en todo el mundo durante varias horas. Aunque al principio muchos creyeron que se trataba de un ciberataque masivo, la propia Cloudflare aclaró que la falla tuvo un origen interno. Para entender la magnitud del episodio, es importante comprender qué hace esta compañía y por qué su infraestructura es tan crítica para la red.
Cloudflare es una plataforma global de conectividad que protege y acelera sitios web, aplicaciones y servicios digitales. Su red procesa alrededor del 20% del tráfico web mundial y ofrece seguridad, rendimiento y herramientas de desarrollo a empresas, instituciones y usuarios de todos los tamaños. Cuando Cloudflare falla, una porción enorme de Internet también lo hace.
La empresa explicó en un informe detallado qué ocurrió, cómo se expandió el problema y qué medidas están tomando para evitar que la situación se repita.
Un error interno que desencadenó la falla
La causa de la caída global de Internet fue un error interno provocado por un cambio en los permisos de una base de datos. Ese ajuste hizo que un archivo esencial usado por el sistema de gestión de bots duplicara su tamaño.
Este archivo, llamado feature file, se distribuye automáticamente a todas las máquinas de la red de Cloudflare y es leído por el software encargado de enrutar el tráfico. El problema: ese software tenía un límite de tamaño para el archivo, y la versión duplicada superaba ese umbral, provocando un fallo.
Cuando los servidores empezaron a recibir el archivo “inflado”, los procesos internos comenzaron a fallar. Esto generó errores 5xx visibles para los usuarios y dejó inaccesibles millones de páginas web.
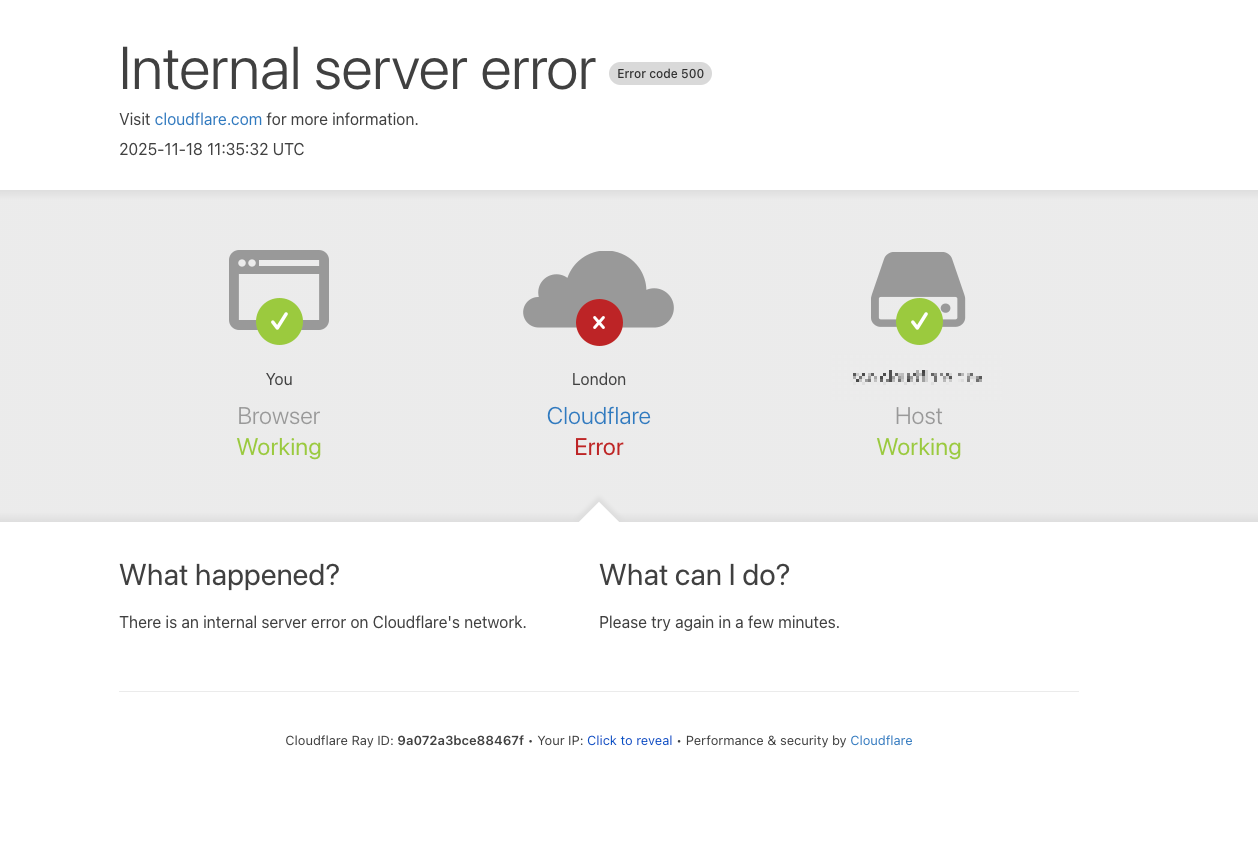
La fluctuación inicial del fallo complicó el diagnóstico. Durante varios minutos, algunas máquinas generaban el archivo correcto y otras no, lo que hacía que la red se recuperara parcialmente antes de volver a fallar.
Cómo se propagó el problema a nivel global
El origen técnico estuvo en una consulta realizada sobre un clúster de bases de datos ClickHouse. El cambio en los permisos permitió que la consulta devolviera filas duplicadas provenientes de una base interna, lo que generó un archivo mal formado.
Ese archivo se propagaba cada cinco minutos en toda la red. Como no todas las máquinas estaban actualizadas de inmediato, el fallo aparecía y desaparecía, creando un patrón errático que inicialmente confundió al equipo de ingeniería.
Una vez que todos los nodos generaron la versión incorrecta del archivo, el problema se estabilizó en un estado de falla total.
Servicios clave como el CDN de Cloudflare, el sistema de protección contra bots, el dashboard de administración, Access y Workers KV se vieron afectados a diferentes niveles.
La respuesta de Cloudflare durante la crisis
El equipo técnico inicialmente sospechó que se trataba de un ataque DDoS a gran escala debido a los síntomas. También coincidió que la página de estado de la compañía sufrió una caída externa, lo que alimentó aún más esa hipótesis.
Sin embargo, al analizar los archivos de configuración y los patrones de error, identificaron el origen real del problema: el archivo duplicado generado por la base de datos. Una vez localizado, detuvieron su propagación y restauraron una versión previa.
A las 14:30 UTC, el tráfico comenzó a fluir nuevamente. A las 17:06, todos los servicios funcionaban con normalidad.
Cloudflare destacó que, aunque la recuperación fue relativamente rápida, la magnitud del incidente lo convierte en su peor apagón desde 2019.
Qué hará Cloudflare para evitar nuevas fallas
Tras la caída global de Internet, la empresa anunció una serie de medidas para reforzar su resiliencia:
- Endurecer la validación de archivos de configuración generados internamente.
- Habilitar interruptores globales de emergencia para detener despliegues problemáticos.
- Evitar que informes de errores o volcados de memoria saturen recursos.
- Revisar modos de falla en todos los módulos críticos del proxy.
La compañía reconoció la gravedad del incidente y pidió disculpas públicas, afirmando que su infraestructura debe ser lo suficientemente robusta para evitar interrupciones de este alcance.
Una red más resiliente hacia el futuro
La caída global de Internet evidenció cuán interdependiente es la red moderna y cómo una falla en un único componente puede escalar hasta afectar a usuarios en todo el mundo. Cloudflare aseguró que reforzará sus sistemas para que un error interno no vuelva a paralizar vastas zonas de la red.
ℹ️
Si tienes dudas sobre este contenido, puedes solicitar las fuentes utilizadas para su desarrollo en nuestra zona de contacto adjuntando la URL de esta misma.








